
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 이분그래프판별
- Java
- OS
- 해시
- 프로그래머스
- 동적계획법
- 2색칠하기
- Algorithm
- Lv.1
- 파이썬
- 고득점Kit
- C++
- 알고리즘
- 운영체제
- 코테준비
- hash
- 코딩테스트준비
- 면접질문
- 그래프
- BFS
- 쿠쉬쿠쉬
- 코딩테스트
- 문제풀이
- Python
- C
- 단지번호붙이기
- LV.3
- Lv.2
- BruteForceSearch
Archives
- Today
- Total
쿠쿠의기록
[OS] - 운영체제 (CPU 스케줄링) 본문
- 목차 -
1. CPU 스케줄러
2. 디스패처
3. 스케줄링의 성능 평가
4. 스케줄링 알고리즘
5. 스케줄링 알고리즘의 평가
1. CPU 스케줄러

- CPU 스케줄러 : Ready 상태의 프로세스 중에서 어떤 프로세스에게 CPU를 할당할지 결정
- 종류 : 장기, 중기, 단기 스케줄링
- 장기
- 가장 큰 틀의 CPU 스케줄링 (고수준 스케줄링, 작업 스케줄링)
- 프로세스에 Memory(및 각종 자원)을 주는 문제를 스케줄링 함
- 전체 시스템의 부하를 고려해 작업 요청을 받을지, 거부할지에 대한 결정
(즉 new 상태의 프로세스를 admitted 하는 작업을 장기 스케줄러 진행) - 장기스케줄링의 결정에 따라 시스템 내의 프로세스 총 개수(degree of multiprogramming)가 정해짐
- 최근 운영체제에서는 보통 장기 스케줄러가 없음(프로그램을 실행시키면 곧바로 ready 상태)
- 중기
- 장기스케줄링 - 프로세스의 활성화 승인 다룸 / 중기 스케줄링 - 이미 활성화가 된 프로세스들에 대한 관리
- 시스템의 과부하를 막기 위해 활성화된 프로세스들의 중지 여부를 결정하여 활성화된 프로세스 수를 조절
(여유 공간 마련을 위해 프로세스를 통째로 메모리에서 디스크로 쫓아냄 => Swap out) - degree of multiprogramming을 제어
- 중기 스케줄링에 의해 중지된 프로세스들은 보류 상태(Suspended, Stopped)가 됩니다.
- 단기
- 가장 작은 단위의 스케줄링을 단기 스케줄링
- 어떤 프로세스에 CPU를 할당할지, 어떤 프로세스를 대기 상태로 보낼지 등을 결정
- 어떤 기준에 따라 프로세스를 선택(스케줄링 알고리즘)하고 어느 정도 자원을 배분(Time slice와 관련)할지에 따라 시스템에 큰 영향을 끼침
- 장기

- CPU 스케줄링이 필요한 경우
- 비선점형 방식(CPU를 획득한 프로세스가 CPU를 반납하기 전까지는 CPU를 빼앗기지 않는 방법)
- 실행 상태에 있던 프로세스가 I/O 요청 등에 의해 봉쇄(blocked) 상태로 바뀌는 경우
- CPU에서 실행 상태에 있는 프로세스가 종료되는 경우

- 선점형 방식(프로세스가 CPU를 계속 사용하기를 원하더라도 강제로 빼앗을 수 있는 스케줄링 방법)
- 실행 상태에 있던 프로세스가 타이머 인터럽트 발생에 의해 준비 상태로 바뀌는 경우
- I/O 요청 => 봉쇄 상태에 있던 프로세스의 I/O 작업이 완료(인터럽트가 발생) => 프로세스 준비 상태로 변경
(단, I/O 작업이 완료된 프로세스가 인터럽트 당한 프로세스보다 우선순위가 높아, 인터럽트 처리 후 이전에 수행되던 프로세스가 아닌 I/O 작업이 완료된 프로세스로 CPU가 할당되는 경우에 해당)
- 비선점형 방식(CPU를 획득한 프로세스가 CPU를 반납하기 전까지는 CPU를 빼앗기지 않는 방법)
2. 디스패처
- 디스패처 : CPU 스케줄러에 의해 새롭게 선택된 프로세스가 CPU를 할당받고 작업을 수행할 수 있도록 환경설정을 하는 운영체제의 코드
- Context Switch : CPU 제어권을 CPU 스케줄러에 의해 선택된 프로세스에게 넘김
- 단기 스케줄러가 선택한 프로세스에 실질적으로 프로세서 할당하는 역할
- 프로세스 레지스터를 적재 (문맥교환)
- 운영체제 모드(Kernel Mode) => 사용자 상태(User Mode)로 전환
- 프로세스 다시 시작 시, 사용자 프로그램이 올바른 위치 찾도록 함
3. 스케줄링의 성능 평가
- 시스템 관점의 지표
- CPU 이용률(CPU utilization)
- 전체 시간 중에서 CPU가 일을 한 시간의 비율
- CPU가 idle 상태에 머무르는 시간을 최대한 줄이는 것이 스케줄링의 중요한 목표가 된다
- 처리량(throughout)
- 주어진 시간 동안 준비 큐에서 기다리고 있는 프로세스 중 몇 개를 끝마쳤는지를 나타냄
(CPU 버스트를 완료한 프로세스의 개수) - CPU의 서비스를 원하는 프로세스 중 몇 개가 원하는 만큼의 CPU를 사용하고 이번 CPU 버스트를 끝내어 준비 큐를 떠났는지 측정한 것
- 주어진 시간 동안 준비 큐에서 기다리고 있는 프로세스 중 몇 개를 끝마쳤는지를 나타냄
- CPU 이용률(CPU utilization)
- 사용자 관점의 지표
- 소요시간(turnaround time)
- 프로세스가 CPU를 요청한 시점부터 원하는 만큼 CPU를 다 쓰고 CPU 버스트가 끝날 때까지 걸린 시간
(준비 큐에서 기다린 시간 + 실제로 CPU를 사용한 시간) - 프로그램이 시작해 종료하는 데까지 걸리는 시간이 아님
- 프로세스가 CPU를 요청한 시점부터 원하는 만큼 CPU를 다 쓰고 CPU 버스트가 끝날 때까지 걸린 시간
- 대기시간(waiting time)
- CPU 버스트 기간 중 프로세스가 준비 큐에서 CPU를 얻기 위해 기다린 시간의 합
- 시분할 시스템에서는 한 번의 CPU 버스트 중에도 준비 큐에서 기다린 시간이 여러 번 발생할 수 있다.
- 이번 CPU 버스트가 끝나기까지 준비 큐에서 기다린 시간의 합을 뜻한다.
- 응답시간(response time)
- 프로세스가 준비 큐에 들어온 후 첫 번째 CPU를 획득하기까지 기다린 시간
- 대화형 시스템에 적합한 성능 척도로서 사용자 입장에서 가장 중요한 성능 척도라 할 수 있다.
- 소요시간(turnaround time)
4. 스케줄링 알고리즘
1) 선입선출 (FCFS : First-Come First-Served)
- 프로세스가 준비 큐에 도착한 시간 순서대로 CPU를 할당하는 방식

2) 최단작업 우선 (SJF : Shortest-Job First)
- CPU 버스트가 가장 짧은 프로세스에게 제일 먼저 CPU를 할당하는 방식
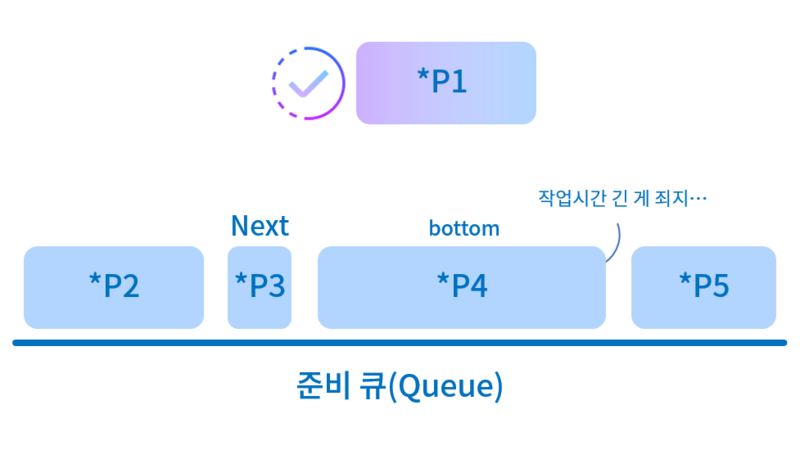
3) 우선순위 (Priority)
- 준비 큐에서 기다리는 프로세스들 중 우선순위가 가장 높은 프로세스에게 제일 먼저 CPU를 할당하는 방식
4) 라운드 로빈 (Round Robin)
- 각 프로세스가 CPU를 연속적으로 사용할 수 있는 시간이 정해져있으며, 이 시간이 경과하면 해당 프로세스로부터 CPU를 회수해 준비 큐에 줄 서 있는 다른 프로세스에게 CPU를 할당

5) 멀티레벨 큐 (Multi-Level Queue)
- 준비 큐를 여러 개로 분할해 관리하는 스케줄링(프로세스들이 CPU를 기다리기 위해 여러 줄로 서 있는 것)

6) 멀티레벨 피드백 큐 (Multi-Level Feedback Queue)
- 멀티레벨 큐와 동일하나, 프로세스가 하나의 큐에서 다른 큐로 이동 가능하다는 점이 다르다.
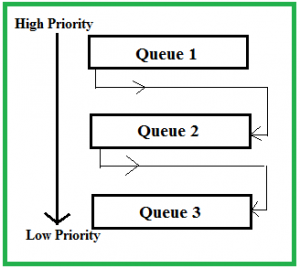

Multilevel Feedback Queue의 대표적인 구현 예시
5. 스케줄링 알고리즘의 평가
- 알고리즘 선택하는 방법
- 사용할 기준 정의
- 선택 기준에 따라 알고리즘들 평가
1) 결정론적 모델링(Deterministic Modeling)
- 분석적 평가(analytic evaluation) : 알고리즘 성능 평가 공식 / 값을 생성하기 위해 알고리즘과 시스템 부하를 이용
- 결정론적 모델링(deterministic modeling) : 미리 정의된 특정 작업 부하를 이용하여 각 알고리즘의 성능을 정의
장점 : 단순하고 빠르고, 알고리즘 비교를 위한 정확한 값을 제공
단점 : 입력으로 정확한 숫자를 요구하고, 결과 또한 입력된 경우에 대해서만 적용
2) 큐잉 모델(Queueing Models)
- 대부분 시스템에서 실행되는 프로세스 매일 달라짐
- 두 분포로부터 대부분 알고리즘 여러 값들 계산 가능
- CPU와 I/O bust의 분포
- arrival-time 분포
- 네트워크 분석(queueing-network analysis)
- 도착률(arrival rate), 서비스율(service rate)을 통해서 이용률(utilization), 평균 큐 길이, 평균 대기 시간 등을 계산
- Little's formula
- n을 평균 큐 길이, W를 큐에서의 평균 대기 시간, λ를 새로운 프로세스들이 도착하는 평균 도착률이라 하면
- n = λ x W을 만족
- 큐잉 모델의 한계
- 처리 가능한 알고리즘과 분포가 제한적
- 복잡한 알고리즘과 분포의 수학적 분석이 어려움
- 실제 시스템의 근사치이므로, 계산 결과의 정확성에 의심의 여지가 있다
3) 모의실험(Simulation)
- 컴퓨터 시스템에 대한 모델을 프로그래밍하는 것을 포함
- 모의실험을 위한 데이터 생성 방법
- 난수 발생기(ramdom-number generator) 사용
- 추적 파일(trace file) 사용
(추척 파일은 실제 시스템을 모니터 해서 이벤트의 순서를 기록해놓은 파일)
- 모의 실험의 단점
- 컴퓨터를 오래 사용해야 하므로 큰 비용이 발생할 수 있음
- 추적 파일은 대량의 저장 공간을 요구할 수 있음
4) 구현(Implementation)
- 실제 코드로 작성해 os에 넣고 실행해 보는 방법으로 알고리즘을 평가하는 유일하게 정확한 방법
- 구현의 단점
- 비용이 많이 듬
- 알고리즘 적용 환경이 바뀔 수 있음
출처
- https://coding-gongbu.tistory.com/39
- https://hyunah030.tistory.com/4
- https://one10004.tistory.com/136
- https://velog.io/@ss-won/OS-CPU-Scheduler%EC%99%80-Dispatcher
'개발에 대한 기본 지식 > 운영체제' 카테고리의 다른 글
| [OS] - 운영체제 (프로세스 관리) (0) | 2023.12.01 |
|---|---|
| [OS] - 운영체제 (프로그램의 구조와 실행) (2) | 2023.11.27 |
| [OS] - 운영체제 (컴퓨터 시스템 동작 원리) (0) | 2023.11.13 |
| [OS] - 운영체제 (정의, 기능, 분류, 예, 자원 관리 기능) (0) | 2023.11.10 |
'개발에 대한 기본 지식/운영체제' Related Articles
more



